- Apache Kafka (opens new window) 是采用 Scala 语言开发的一个分布式、多分区、多副本且基于 ZooKeeper 协调的用于处理数据流的分布式消息框架。(新版本已逐步转向使用 KRaft 模式来替代 ZooKeeper)
- 消息生产者向 Kafka 服务器发送消息,Kafka 接收消息后,再投递给消费者。
- 在 Kafka 中,生产者的消息会被发送到 Topic 中,Topic 中保存着各类数据,每一条数据都使用键、值进行保存。
- 每一个 Topic 中都包含一个或多个物理分区(Partition)。这些分区维护着消息的内容和索引,它们有可能被保存在不同的服务器中。
- 消费者会为自己添加一个消费者组的标识(Group),每一条发布到 Topic 的记录,都会被交付给消费者组的一个消费者实例。
- 如果多个消费者实例拥有相同的消费者组,那么这些记录将会分配到各个消费者实例上,以达到负载均衡的目的。
- 如果所有的消费者都有不同的消费者组,那么每一条记录都会被广播到全部的消费者进行处理。
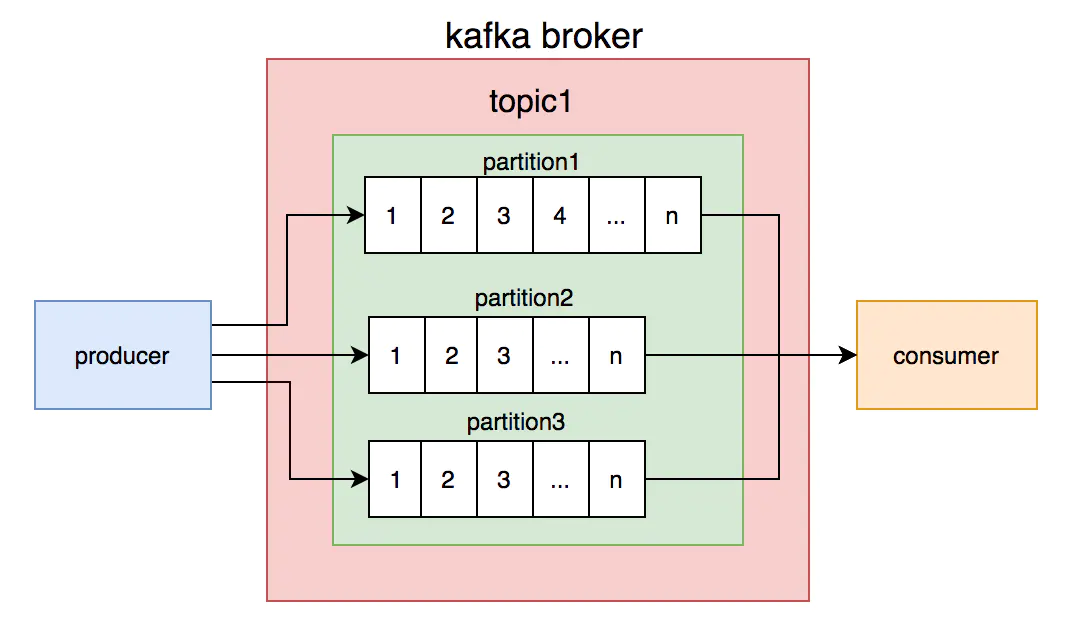
# 工作流程
- 生产者将消息发送到指定 Topic 的某个 Partition
- 每个 Partition 有多个副本(Replica),包括一个 Leader 和多个 Follower
- 消费者采用**拉取(Pull)**模式从 Broker 获取消息
# 最佳实践 (opens new window)
# 发布者最佳实践
发送确认:acks,默认值 1,服务端主节点写成功即返回 Response,性能中等、丢数据风险中等、主节点宕机可能导致数据丢失。
批量发送:Producer 客户端在向服务端发送消息时,需要先确认往哪个 Topic 的哪个分区发送。给同一个分区发送多条消息时,Producer 客户端将相关消息打包成一个 Batch,批量发送到服务端。一个合适的 Batch 大小,可以减少发送消息时客户端向服务端发起的请求次数,在整体上提高消息发送的吞吐和延迟。相关参数:
- batch.size:发往每个分区的消息缓存量(消息内容的字节数之和,不是条数)。达到设置的数值时,就会触发一次网络请求,然后 Producer 客户端把消息批量发往服务器。默认值 16384,单位:字节。
- linger.ms:每条消息在缓存中的最长时间。若超过这个时间,Producer 客户端就会忽略 batch.size 的限制,立即把消息发往服务器。建议根据业务场景,设置 linger.ms 在 100~1000 之间。默认值 0,单位:毫秒。
分区策略:partitioner.class,默认值 DefaultPartitioner.class,策略:
- 使用指定的分区
- 未指定分区时,对消息的 Key 进行哈希(Murmur2Hash),然后根据哈希结果选择分区
- 未指定分区,也未提供 Key 时,粘性分区(随机选择一个分区并“粘”在上面,Batch 完成后再随机选择另一个分区)
# 订阅者最佳实践
- 订阅者在订阅消息时的基本流程为:Poll 数据 → 执行消费逻辑 → 再次 Poll 数据

订阅方式:
- 一个 Group 可以订阅多个 Topic,多个 Topic 的消息被 Group 中的 Consumer 均匀消费
- 一个 Topic 可以被多个 Group 订阅,且各个 Group 独立消费 Topic 下的所有消息
负载均衡:
- 一个 Topic 的所有分区被平均分配给同一个 Group 内的各个消费实例,一个分区最多只能被同一个 Group 内的一个消费者实例消费。因此消费实例的个数不要大于分区的数量,否则会有消费实例分配不到任何分区而处于空跑状态。
- 消费者实例发生重启、增加、减少等变更时,都会触发一次负载均衡。
分区个数:
- 系统的最大并行度(吞吐量上限)由 Topic 的分区数量决定
- Kafka 的存储和协调机制是以分区为粒度的:分区数过多,会导致存储碎片化严重,集群性能和稳定性都会急剧下降;分区数过少,会导致整体吞吐量不足
- 分区增加后,将不能减少
- 建议分区数是消费者数量的整数倍(不小于 12,不超过 100),避免出现 Topic 分区倾斜
消费位点提交:消费者默认会每隔 5s 自动将当前消费到的偏移量提交到 Kafka。相关参数:
- enable.auto.commit:是否采用自动提交位点机制,默认值为 true
- auto.commit.interval.ms:自动提交位点时间间隔,默认值为 5000,即 5s
提高消费速度:增加 Consumer 实例个数、增加消费线程(把数据提交到线程池进行并发处理)
消息重复和消费幂等:
- Kafka 消费语义是 at least once,即至少投递一次,保证消息不丢失,但是无法保证消息不重复。
- 消息幂等,常用做法:
- 发送消息时,传入 key 作为唯一流水号 ID。
- 消费消息时,判断 key 是否已经消费过,如果已经被消费,则忽略,如果没消费过,则消费一次。
消费失败:失败后一直尝试再次执行消费逻辑
# 通过 Docker 启动 Kafka
- 官方指引
- https://hub.docker.com/r/confluentinc/cp-kafka
- https://docs.confluent.io/current/quickstart/cos-docker-quickstart.html
- 运行镜像
- https://github.com/confluentinc/cp-docker-images,kafka-single-node/docker-compose.yml
- docker-compose up -d
Sponsor